面试-Java并发
1. 进程和线程
1.1 进程
- 当一个程序被运行,从磁盘加载这个程序的代码至内存,这时就开启了一个进程
- 一个进程可以被划分为多个线程
1.2 线程
- 一个线程就是一个指令流,将指令流中的一条条指令以一定的顺序交给 CPU 执行
区别:
- 进程是正在运行程序的实例,进程中包含了线程,每个线程执行不同的任务
- 不同的进程使用不同的内存空间,在当前进程下的所有线程可以共享内存空间
- 线程更轻量,线程上下文切换成本一般上要比进程上下文切换低(上下文切换指的是从一个线程切换到另一个线程)
2. 并行并发
- 并发是同一时间应对多件事情的能力,多个线程轮流使用一个或多个CPU
- 并行是同一时间动手做多件事情的能力,4核CPU同时执行4个线程
3. 创建线程的方式
3.1 继承Thread类
1 | |
3.2 实现Runnable接口
1 | |
3.3 实现Callable接口
1 | |
- Callable要配合 FutureTask使用
- Callable能取得执行结果
- 可以抛出异常
3.4 线程池创建
1 | |
start和run启动线程:
- start(): 用来启动线程,通过该线程调用run方法执行run方法中所定义的逻辑代码。start方法只能被调用一次。
- run(): 封装了要被线程执行的代码,可以被调用多次。
4. 线程状态
4.1 状态定义
1 | |
4.2 状态转换
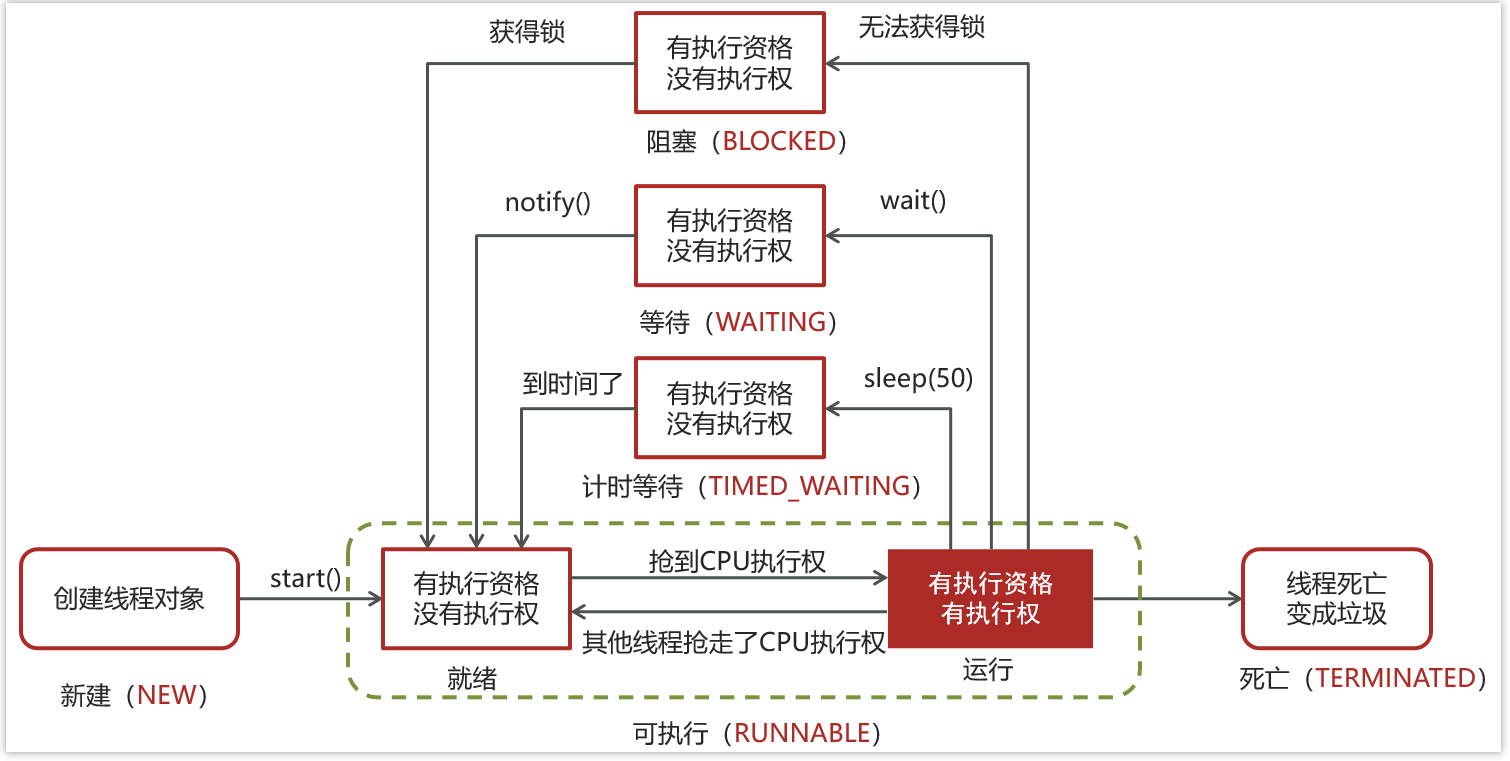
- 创建线程对象是新建状态
- 调用了start()方法转变为可执行状态
- 线程获取到了CPU的执行权,执行结束是终止状态
- 在可执行状态的过程中,如果没有获取CPU的执行权,可能会切换其他状态
- 如果没有获取锁(synchronized或lock)进入阻塞状态,获得锁再切换为可执行状态
- 如果线程调用了wait()方法进入等待状态,其他线程调用notify()唤醒后可切换为可执行状态
- 如果线程调用了sleep(50)方法,进入计时等待状态,到时间后可切换为可执行状态
5. 线程交替打印
5.1 使用synchronized
1 | |
5.2 使用reentrantlock
1 | |
5.3 使用信号量
Semaphore 的工作原理:
Semaphore.acquire():当前线程尝试获取信号量。如果信号量的值大于零,则获取成功,信号量的值减一;如果信号量的值等于零,则线程阻塞,直到有其他线程释放信号量。Semaphore.release():释放信号量,信号量的值加一,并唤醒阻塞在该信号量上的一个线程(如果有)。
1 | |
6. 按照顺序打印线程
1 | |
xx.join():会等到xx线程执行完毕之后,当前线程才能执行
7. notify和notifyAll
- notifyAll:唤醒所有wait的线程
- notify:只随机唤醒一个 wait 线程
8. wait和sleep
相同点:
- wait() ,wait(long) 和 sleep(long) 的效果都是让当前线程暂时放弃 CPU 的使用权,进入阻塞1状态
不同点:
方法归属不同
sleep(long) 是 Thread 的静态方法
而 wait(),wait(long) 都是 Object 的成员方法,每个对象都有
醒来时机不同
- 执行 sleep(long) 和 wait(long) 的线程都会在等待相应毫秒后醒来
- wait(long) 和 wait() 还可以被 notify 唤醒,wait() 如果不唤醒就一直等下去
- 它们都可以被打断唤醒
锁特性不同(重点)
- wait 方法的调用必须先获取 wait 对象的锁,而 sleep 则无此限制
- wait 方法执行后会释放对象锁,允许其它线程获得该对象锁(我放弃 cpu,但你们还可以用)
- 而 sleep 如果在 synchronized 代码块中执行,并不会释放对象锁(我放弃 cpu,你们也用不了)
- wait 方法的调用必须先获取 wait 对象的锁,而 sleep 则无此限制
wait必须要配合synchronized使用
9. synchornized底层原理
Synchronized【对象锁】采用互斥的方式让同一时刻至多只有一个线程能持有【对象锁】,其它线程再想获取这个【对象锁】时就会阻塞住
使用
javap -v xx.class查看class字节码信息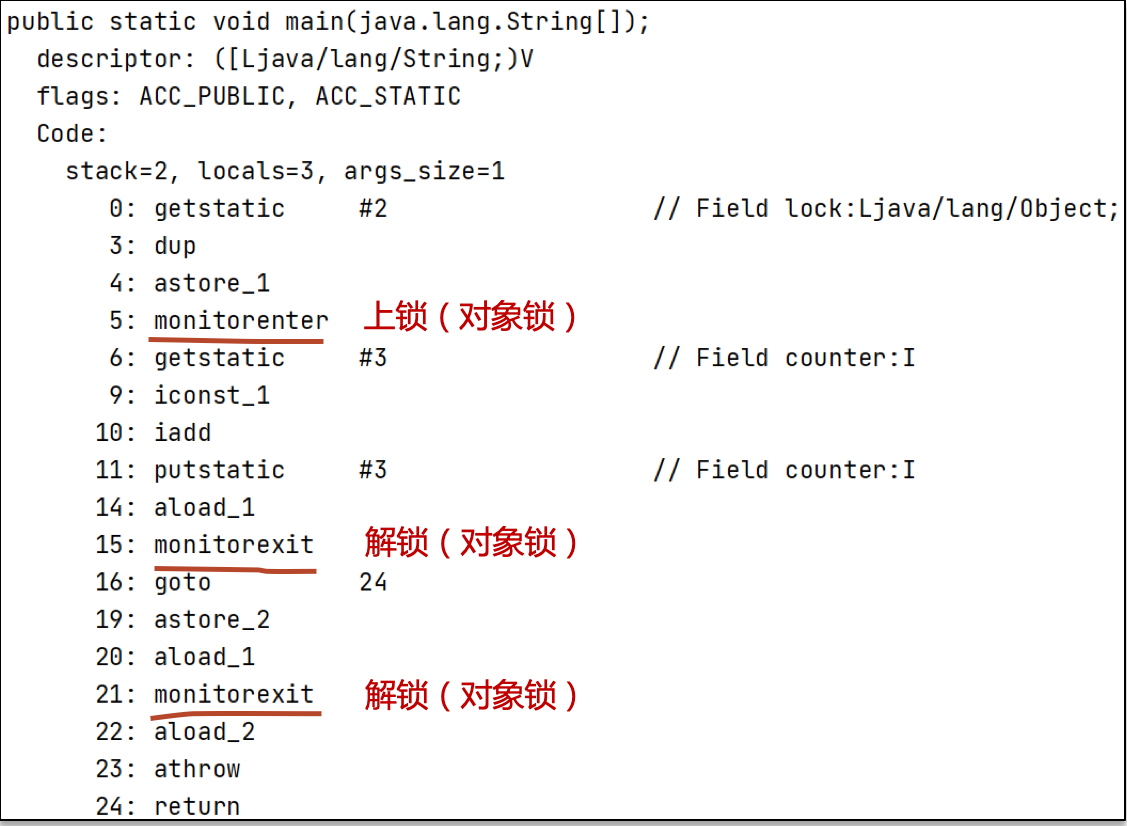
可以看到有两次解锁的行为,即:防止在加锁之后执行出现异常而没有正常的释放掉锁
9.1 Monitor
- Monitor 被翻译为监视器,是由jvm提供,c++语言实现。
- lMonitor实现的锁属于重量级锁,里面涉及到了用户态和内核态的切换、进程的上下文切换,成本较高,性能比较低。
9.1.1. Monitor结构

- Owner:存储当前获取锁的线程的,只能有一个线程可以获取
- EntryList:关联没有抢到锁的线程,处于Blocked状态的线程
- WaitSet:关联调用了wait方法的线程,处于Waiting状态的线程
9.1.3 如何将对象关联到Monitor
在HotSpot虚拟机中,对象在内存中存储的布局可分为3块区域:对象头(Header)、实例数据(Instance Data)和对齐填充
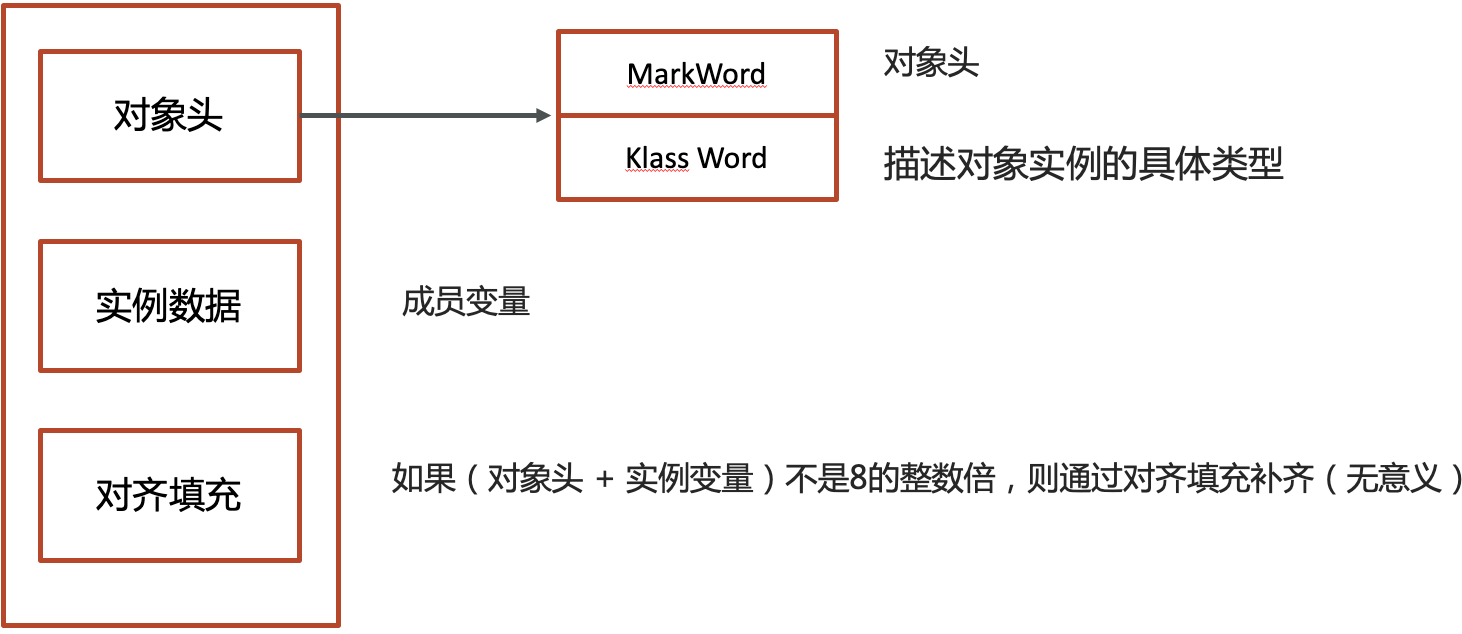
即:通过对象头的mark word就可以实现和monitor关联
9.1.3.1 MarkWord

- hashcode:25位的对象标识Hash码
- age:对象分代年龄占4位(表示GC之后存活的次数)
- biased_lock:偏向锁标识,占1位 ,0表示没有开始偏向锁,1表示开启了偏向锁
- thread:持有偏向锁的线程ID,占23位
- epoch:偏向时间戳,占2位(获得锁的时间戳)
- ptr_to_lock_record:轻量级锁状态下,指向栈中锁记录的指针,占30位
- ptr_to_heavyweight_monitor:重量级锁状态下,指向对象监视器Monitor的指针,占30位
9.2 偏向锁
1 | |
- 轻量级锁在没有竞争时(就自己这个线程),每次重入仍然需要执行 CAS 操作。(CAS消耗CPU)
- 如果这个锁只被一个线程持有,没有与任何其他线程形成竞争,那么此时锁为偏向锁
- Java 6 中引入了偏向锁来做进一步优化:只有第一次使用 CAS 将线程 ID 设置到对象的 Mark Word 头,之后发现这个线程 ID 是自己的就表示没有竞争,不用重新 CAS。以后只要不发生竞争,这个对象就归该线程所有
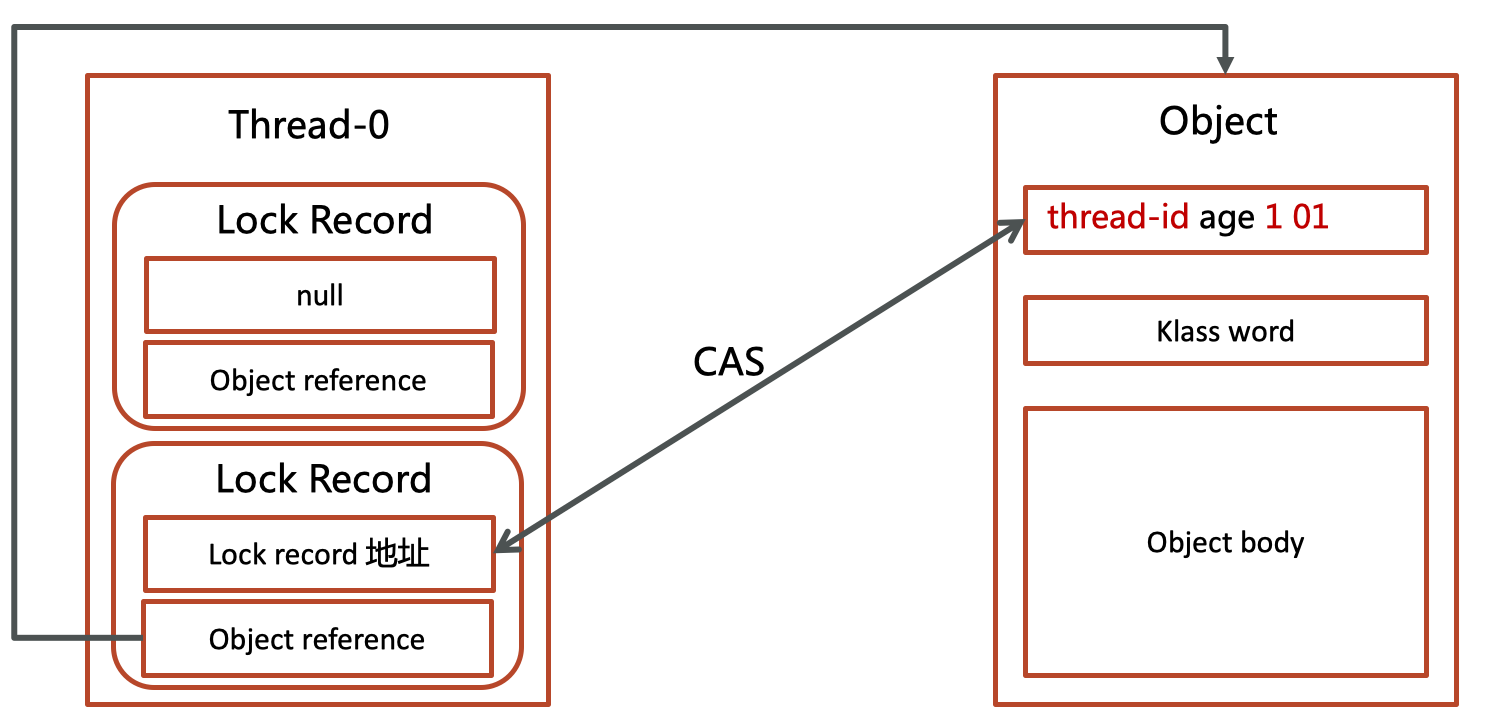
- 第一次使用CAS将当前线程id设置到对象头的markword中,当第二次再进入的时候,当前线程发现对象头中markword中的线程id是自己的,就不会再进行CAS了
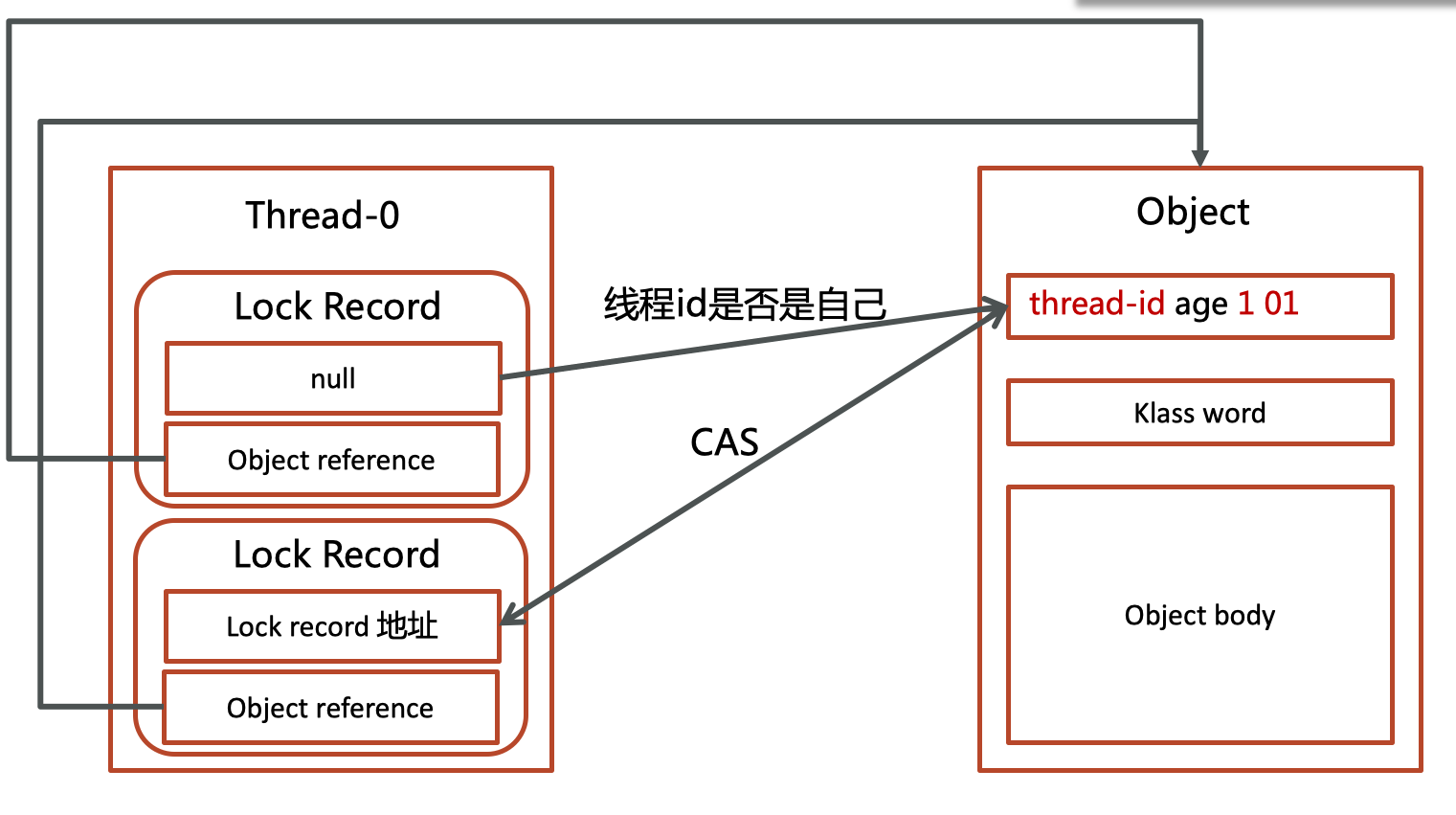
9.3 轻量级锁
1 | |
9.3.1 加锁过程
在线程栈中创建一个Lock Record,将其obj字段指向锁对象。
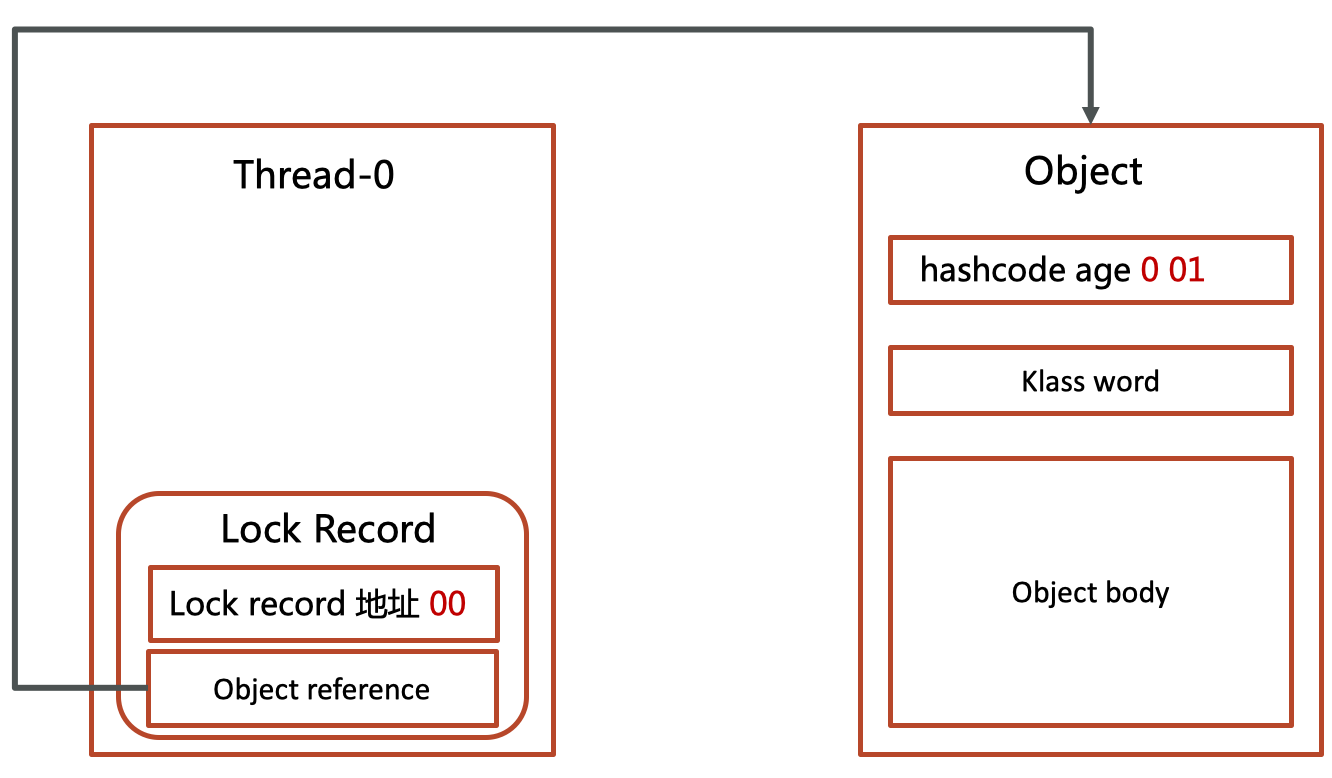
如果此时对象没有被任何线程持有作为锁,那么后面三位是001
通过CAS指令将Lock Record的地址存储在对象头的mark word中,如果对象处于无锁状态则修改成功,代表该线程获得了轻量级锁。
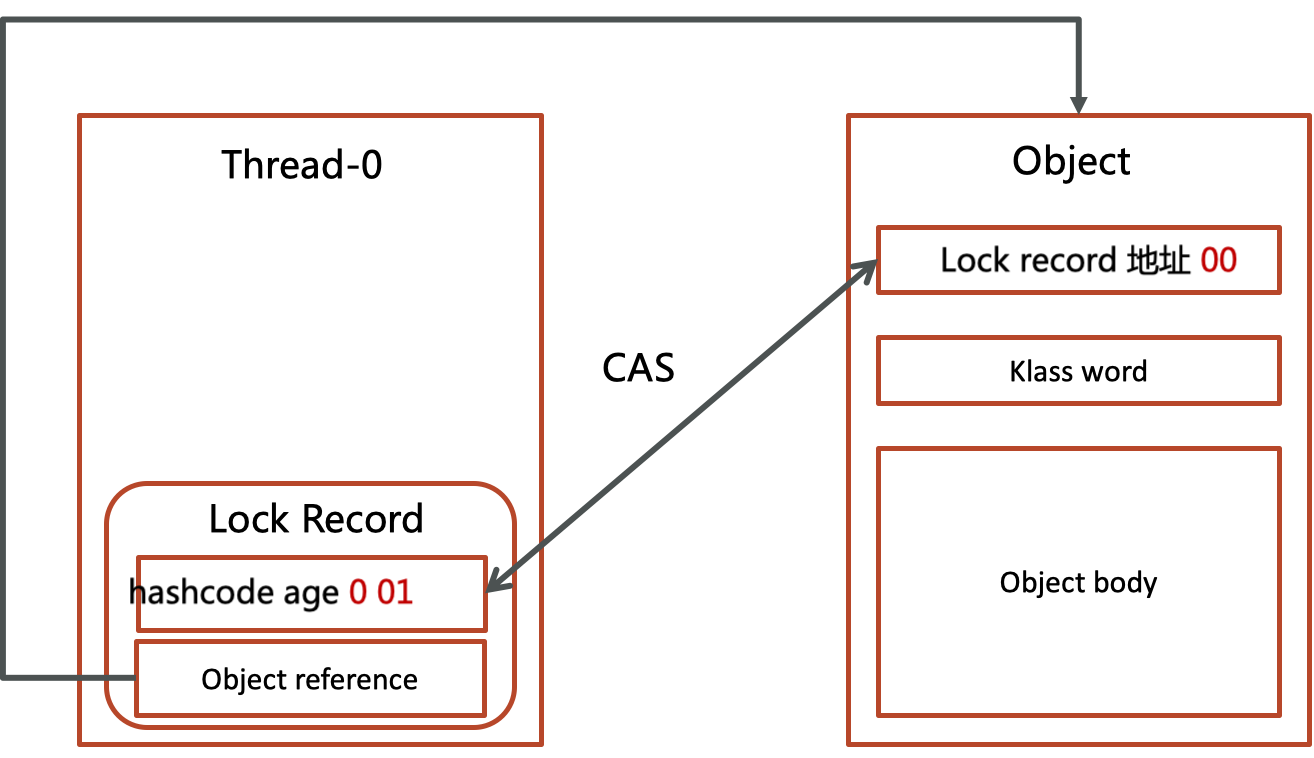
发现obj对象没有被作为锁,那么就进行CAS交换,与obj的markword交换lock record第一部分
如果是当前线程已经持有该锁了,代表这是一次锁重入。还是会进行一次CAS,但是不会真修改对象头中markword中的地址,只是将Lock Record的markwork设为null,起到了一个重入计数器的作用。
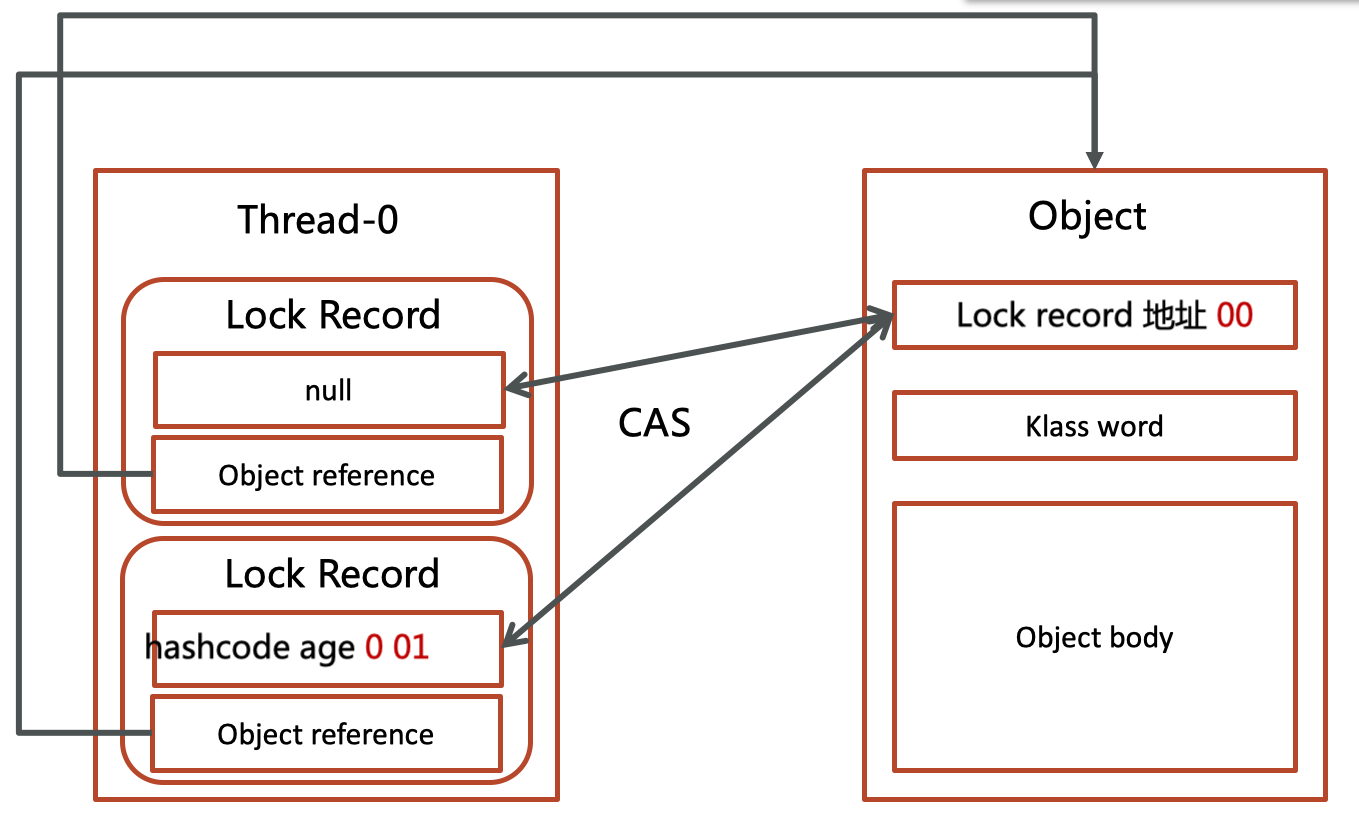
如果CAS修改失败,说明发生了竞争,需要膨胀为重量级锁。
9.3.2 解锁过程
- 遍历线程栈,找到所有obj字段等于当前锁对象的Lock Record。
- 如果Lock Record的Mark Word为null,代表这是一次重入,将obj设置为null后continue。
- 如果Lock Record的 Mark Word不为null,则利用CAS指令将对象头的mark word恢复成为无锁状态。如果失败则膨胀为重量级锁。
9.4 锁升级
- Java中的synchronized有偏向锁、轻量级锁、重量级锁三种形式,分别对应了锁只被一个线程持有、不同线程交替持有锁、多线程竞争锁三种情况。
- 锁升级:无锁->偏向锁->轻量级锁->重量级锁
- 倾向锁:一段很长的时间内都只被一个线程使用锁,可以使用了偏向锁,在第一次获得锁时,会有一个CAS操作,之后该线程再获取锁,只需要判断mark word中是否是自己的线程id即可,而不是开销相对较大的CAS命令
- 轻量级锁:线程加锁的时间是错开的(不会形成竞争),可以使用轻量级锁来优化。轻量级修改了对象头的锁标志,相对重量级锁性能提升很多。每次修改都是CAS操作,保证原子性
- 重量级锁:底层使用的Monitor实现,里面涉及到了用户态和内核态的切换、进程的上下文切换,成本较高,性能比较低。
- 只要发生了锁竞争就一定会升级为重量级锁
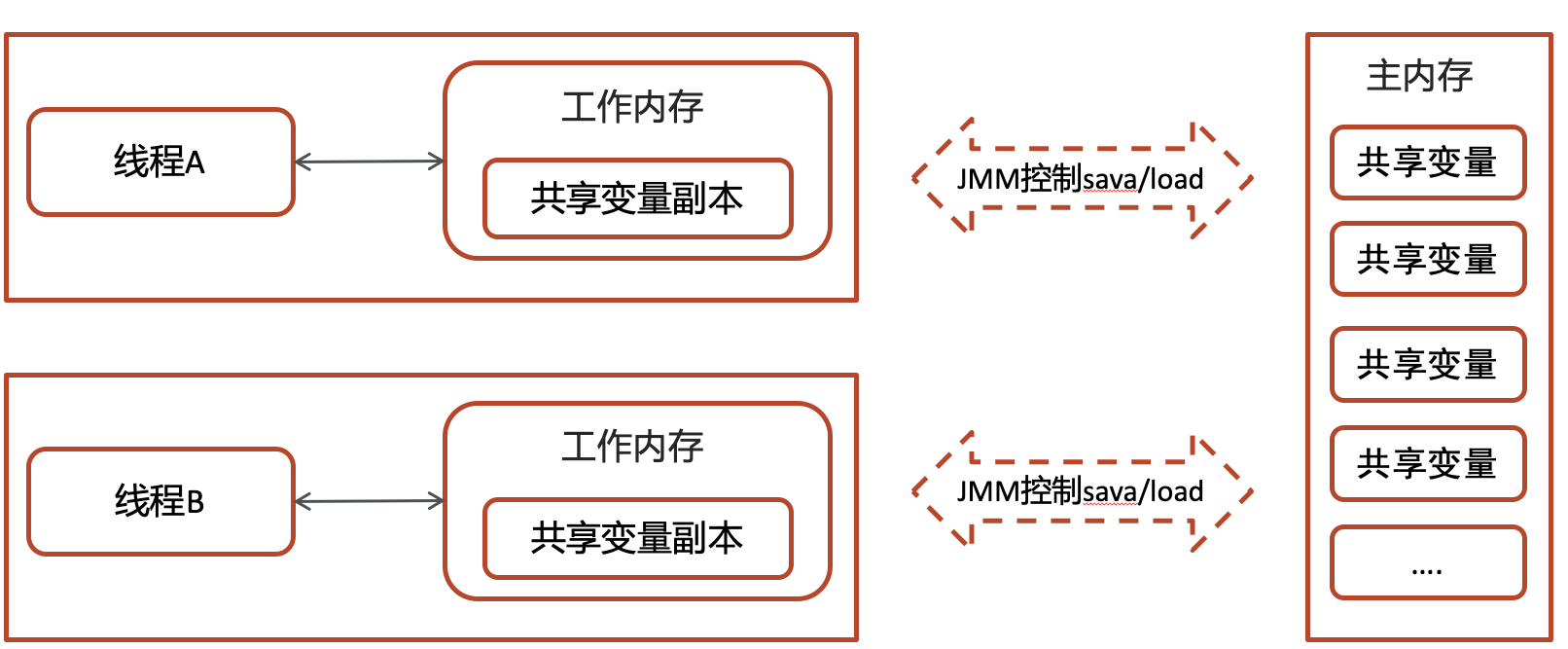
10. Java内存模型
- JMM(Java Memory Model)Java内存模型,定义了共享内存中多线程程序读写操作的行为规范,通过这些规则来规范对内存的读写操作从而保证指令的正确性
- JMM把内存分为两块,一块是私有线程的工作区域(工作内存),一块是所有线程的共享区域(主内存)
- 线程跟线程之间是相互隔离,线程跟线程交互需要通过主内存
11. CAS
- CAS的全称是: Compare And Swap(比较再交换),它体现的一种乐观锁的思想,在无锁情况下保证线程操作共享数据的原子性。
- 一个当前内存值V、旧的预期值A、即将更新的值B,当且仅当旧的预期值A和内存值V相同时,将内存值修改为B并返回true,否则什么都不做,并返回false。
- 如果CAS操作失败,通过自旋的方式等待并再次尝试,直到成功
- cas的底层:CAS 底层依赖于一个 Unsafe 类来直接调用操作系统底层的CAS(原子操作)

- CAS使用到的地方很多:AQS框架、AtomicXXX类
12. volatile
一旦一个共享变量(类的成员变量、类的静态成员变量)被volatile修饰之后,那么就具备了两层语义:
- 保证线程间的可见性
- 禁止进行指令重排序
12.1 线程间可见性
用 volatile 修饰共享变量,能够防止编译器等优化发生,让一个线程对共享变量的修改对另一个线程可见
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29static volatile boolean stop = false;
public static void main(String[] args) {
new Thread(() -> {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
stop = true;
System.out.println(Thread.currentThread().getName()+":modify stop to true...");
},"t1").start();
new Thread(() -> {
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+":"+stop);
},"t2").start();
new Thread(() -> {
int i = 0;
while (!stop) {
i++;
}
System.out.println("stopped... c:"+ i);
},"t3").start();
}在该断代码中,t2线程能在t1线程修改完之后打印stop为true,但是t3线程不会停止,因为因为在JVM虚拟机中有一个JIT(即时编译器)给代码做了优化。将代码
while (!stop)优化为了while (true)因此如果想让t3线程在stop修改为true之后停止,那么在修饰stop变量的时候加上volatile,当前告诉 jit,不要对 volatile 修饰的变量做优化
12.2 禁止指令重排
用 volatile 修饰共享变量会在读、写共享变量时加入不同的屏障,阻止其他读写操作越过屏障,从而达到阻止重排序的效果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21@JCStressTest
@Outcome(id = {"0, 0", "1, 1", "0, 1"}, expect = Expect.ACCEPTABLE, desc = "ACCEPTABLE")
@Outcome(id = "1, 0", expect = Expect.ACCEPTABLE_INTERESTING, desc = "INTERESTING")
@State
public class ReorderTest {
volatile int x;
int y;
@Actor
public void actor1() {
x = 1;
y = 1;
}
@Actor
public void actor2(II_Result r) {
r.r1 = y;
r.r2 = x;
}
}可能得执行结果:
- 先执行actor2获取结果,结果:0,0
- 先执行actor1中的第一行代码,然后执行actor2获取结果,结果:0,1
- 先执行actor1中所有代码,然后执行actor2获取结果,结果:1,1
- 先执行actor1中第二行代码,然后执行actor2获取结果,结果:1,0(此时已经发生指令重排了)
那么将变量添加到volatile可以防止指令重排
写操作:

读操作:

加volatile的技巧:
- 写变量的时候让volatile修饰的变量的在代码最后位置
- 读变量的时候让volatile修饰的变量的在代码最开始位置
13. AQS
全称是 AbstractQueuedSynchronizer,即抽象队列同步器。它是构建锁或者其他同步组件的基础框架
常见的实现类:
- ReentrantLock 阻塞式锁
- Semaphore 信号量
- CountDownLatch 倒计时锁
与synchronized区别:

13.1 工作机制
- 在该类中存在一个state变量,每个线程通过CAS的方式去改变state的值
- state为0表示无锁、state为1表示有锁
- 在AQS内部还有一个队列,当有线程A持有了锁,其他线程会加入到队列中,并且使用HEAD和TAIL进行标记,HEAD指向进入队列最早的元素,TAIL指向进入队列最晚的元素
- 新的线程与队列中的线程共同来抢资源,是非公平锁
- 新的线程到队列中等待,只让队列中的head线程获取锁,是公平锁
14. ReentrantLock原理
特点:
- 可中断
- 可以设置超时时间
- 可以设置公平锁
- 支持多个条件变量
- 与synchronized一样,都支持重入
1
2
3
4
5
6
7
8
9//创建锁对象
ReentrantLock lock = new ReentrantLock();
try {
// 获取锁
lock.lock();
} finally {
// 释放锁
lock.unlock();
}ReentrantLock主要利用CAS+AQS队列来实现。它支持公平锁和非公平锁,两者的实现类似
构造方法接受一个可选的公平参数(默认非公平锁),
- 当设置为true时,表示公平锁,否则为非公平锁。
- 公平锁的效率往往没有非公平锁的效率高,在许多线程访问的情况下,公平锁表现出较低的吞吐量
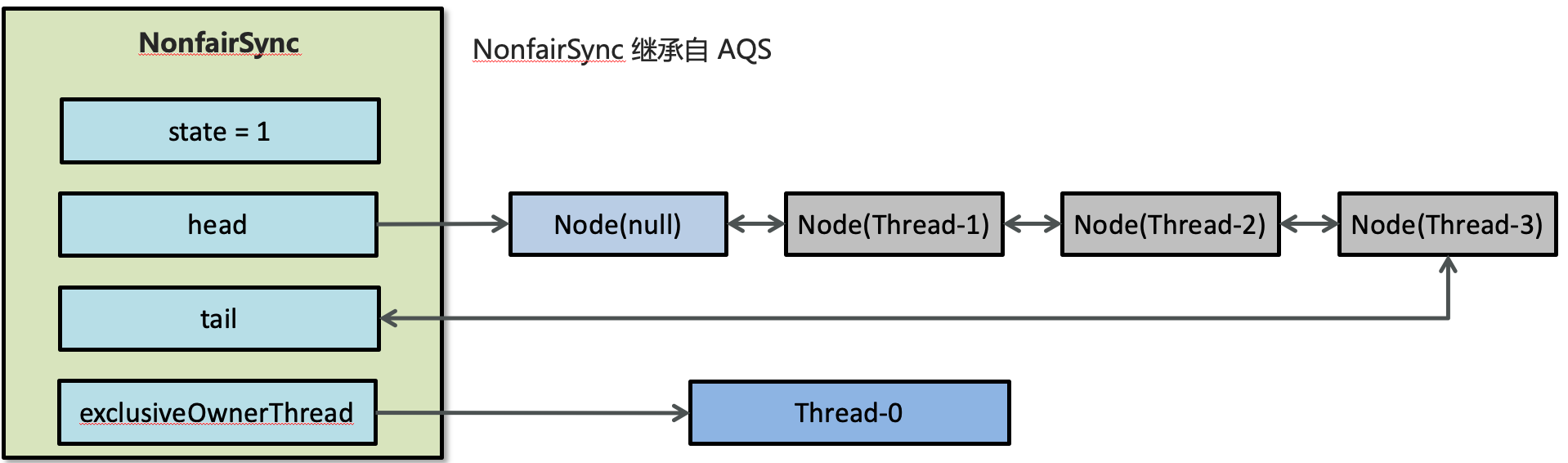
- 线程来抢锁后使用cas的方式修改state状态,修改状态成功为1,则让exclusiveOwnerThread属性指向当前线程,获取锁成功
- 假如修改状态失败,则会进入双向队列中等待,head指向双向队列头部,tail指向双向队列尾部
- 当exclusiveOwnerThread为null的时候,则会唤醒在双向队列中等待的线程
- 公平锁则体现在按照先后顺序获取锁,非公平体现在不在排队的线程也可以抢锁
15. synchoronized和lock区别
- 语法层面
- synchronized 是关键字,源码在 jvm 中,用 c++ 语言实现
- Lock 是接口,源码由 jdk 提供,用 java 语言实现
- 使用 synchronized 时,退出同步代码块锁会自动释放,而使用 Lock 时,需要手动调用 unlock 方法释放锁
- 功能层面
- 二者均属于悲观锁、都具备基本的互斥、同步、锁重入功能
- Lock 提供了许多 synchronized 不具备的功能,例如公平锁、可打断、可超时、多条件变量
- Lock 有适合不同场景的实现,如 ReentrantLock, ReentrantReadWriteLock(读写锁)
- 性能层面
- 在没有竞争时,synchronized 做了很多优化,如偏向锁、轻量级锁,性能还行
- 在竞争激烈时,Lock 的实现通常会提供更好的性能
16. 死锁
死锁:一个线程需要同时获取多把锁,这时就容易发生死锁
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33Object A = new Object();
Object B = new Object();
Thread t1 = new Thread(() -> {
synchronized (A) {
System.out.println(Thread.currentThread().getName()+"-lock A");
try {
sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
synchronized (B) {
System.out.println(Thread.currentThread().getName()+"-lock B");
System.out.println(Thread.currentThread().getName()+"-操作...");
}
}
}, "t1");
Thread t2 = new Thread(() -> {
synchronized (B) {
System.out.println(Thread.currentThread().getName()+"-lock B");
try {
sleep(500);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
synchronized (A) {
System.out.println(Thread.currentThread().getName()+"-lock A");
System.out.println(Thread.currentThread().getName()+"-操作...");
}
}
}, "t2");
t1.start();
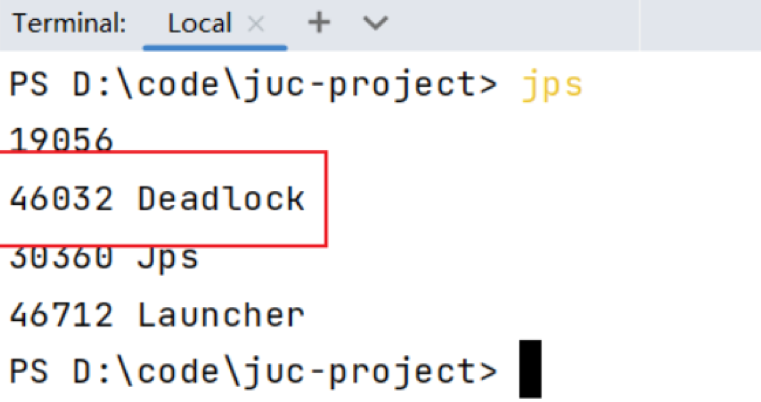
t2.start();当程序出现了死锁现象,我们可以使用jdk自带的工具:jps和 jstack
jps:输出JVM中运行的进程状态信息
jstack:查看java进程内线程的堆栈信息
第一步:输入jps查看运行的线程
第二步:使用jstack查看线程运行的情况,
jstack -I tid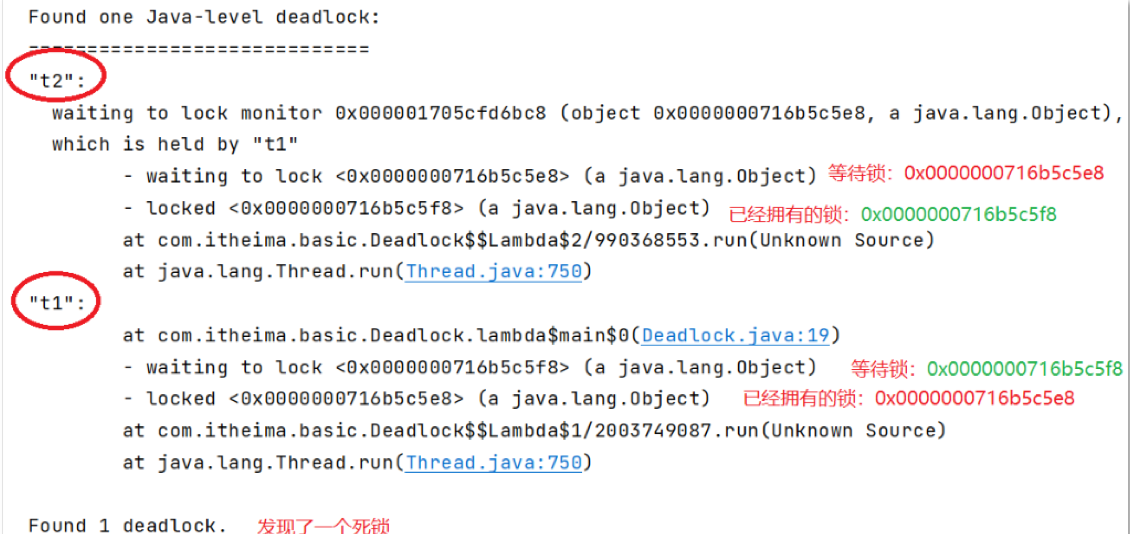
17. ConcurrentHasMap
ConcurrentHashMap 是一种线程安全的高效Map集合
底层数据结构:
- JDK1.7底层采用分段的数组+链表实现
- JDK1.8 采用的数据结构跟HashMap1.8的结构一样,数组+链表/红黑二叉树。
在JDK1.7中:分段数组大小是不能变的
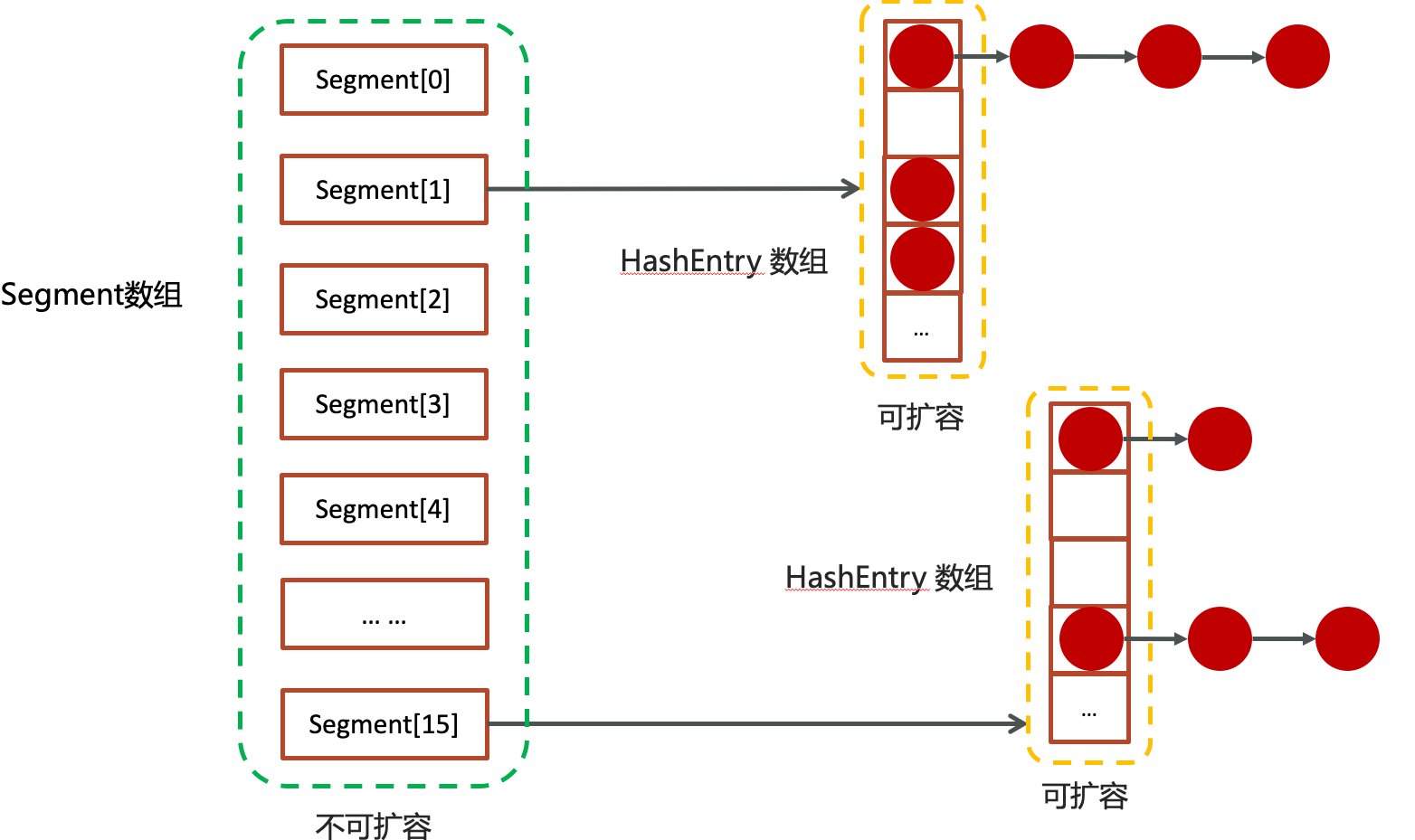
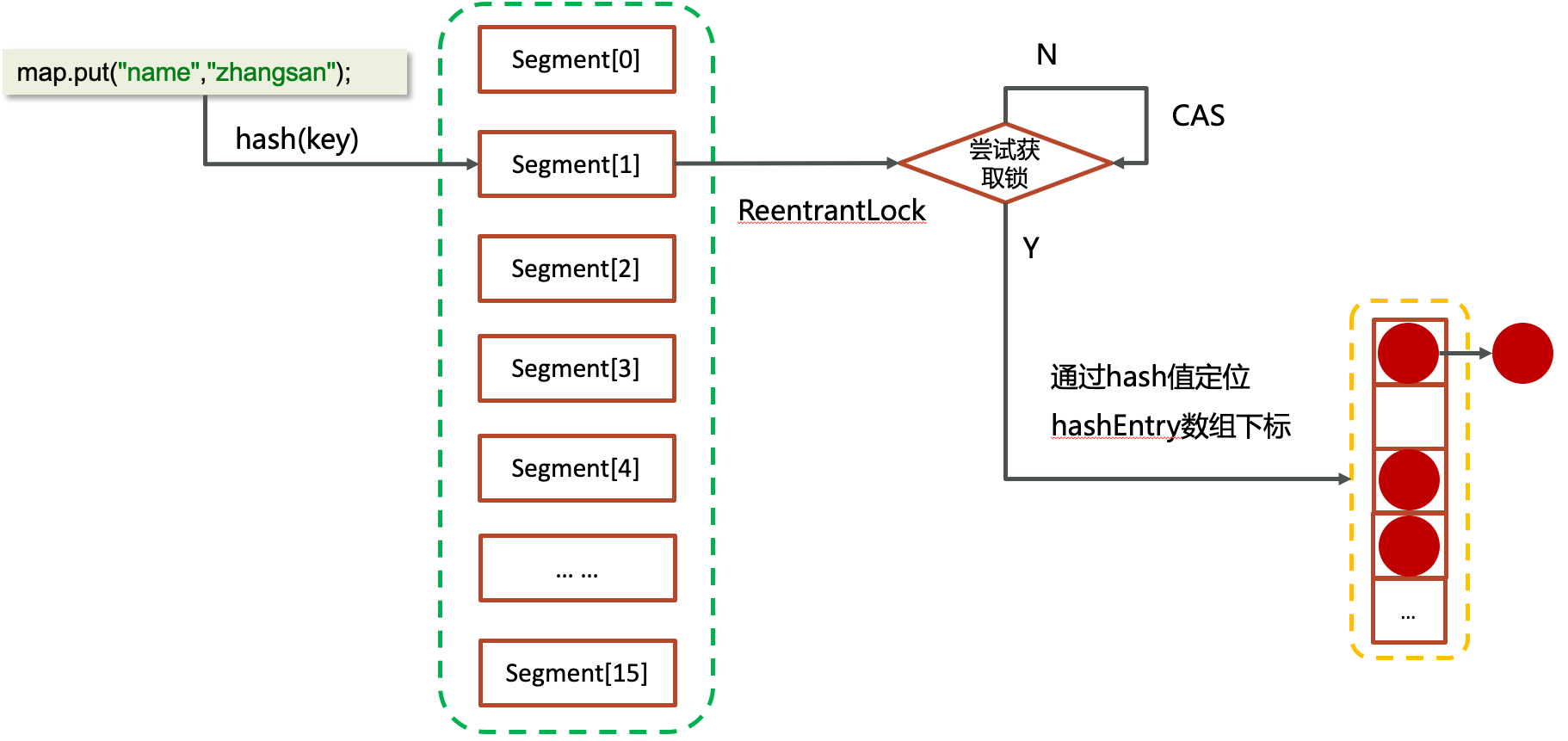
当有元素PUT的时候,会经过hash计算找到在Segment数组中的下标,然后使用ReentrantLock锁住当前Segment(如果在高并发的时候,多个线程就使用CAS的方式尝试获取锁 ),再经过hash值判断要放在hashEntry的哪个位置
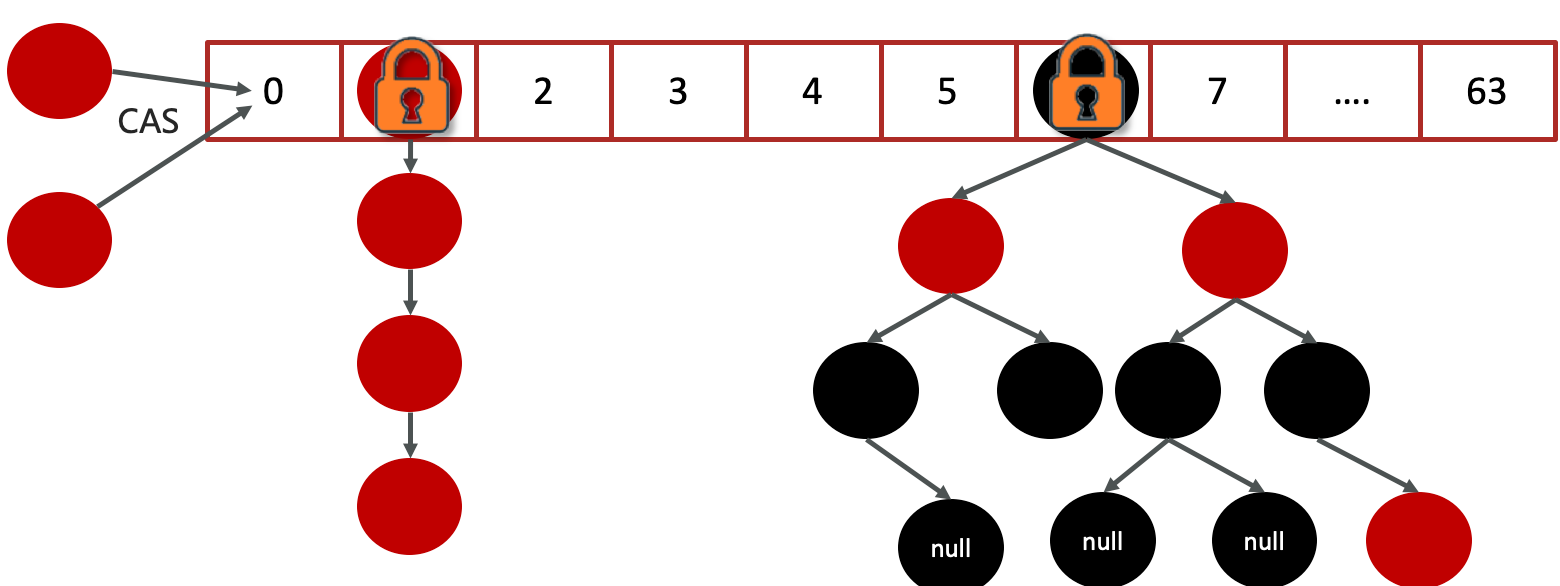
在JDK1.8中,放弃了Segment臃肿的设计,数据结构跟HashMap的数据结构是一样的:数组+红黑树+链表,采用 CAS + Synchronized来保证并发安全进行实现
使用CAS的方式控制相乘对数组节点的添加
synchronized只锁定当前链表或红黑二叉树的首节点,只要hash不冲突,就不会产生并发的问题 , 效率得到提升
18. 并发三大特性
18.1 原子性
- 一个线程在CPU中操作不可暂停,也不可中断,要不执行完成,要不不执行
- 解决:使用sychronized加锁或者使用lock锁,保证只有一个线程操作临界区
18.2 可见性
- 让一个线程对共享变量的修改对另一个线程可见
- 解决:volatile关键字
18.3 有序性
- 指令重排:处理器为了提高程序运行效率,可能会对输入代码进行优化,它不保证程序中各个语句的执行先后顺序同代码中的顺序一致,但是它会保证程序最终执行结果和代码顺序执行的结果是一致的
- 解决:volatile关键字
19. 线程池
构造方法
1
2
3
4
5
6
7public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)核心参数:
- corePoolSize 核心线程数目
- maximumPoolSize 最大线程数目 = (核心线程+非核心线程的最大数目)
- keepAliveTime 生存时间 - 非核心线程的生存时间,生存时间内没有新任务,此线程资源会释放
- unit 时间单位 - 非核心线程的生存时间单位,如秒、毫秒等
- workQueue - 当没有空闲核心线程时,新来任务会加入到此队列排队,队列满会创建救急线程执行任务
- threadFactory 线程工厂 - 可以定制线程对象的创建,例如设置线程名字、是否是守护线程等
- handler 拒绝策略 - 当所有线程都在繁忙,workQueue 也放满时,会触发拒绝策略
执行流程:
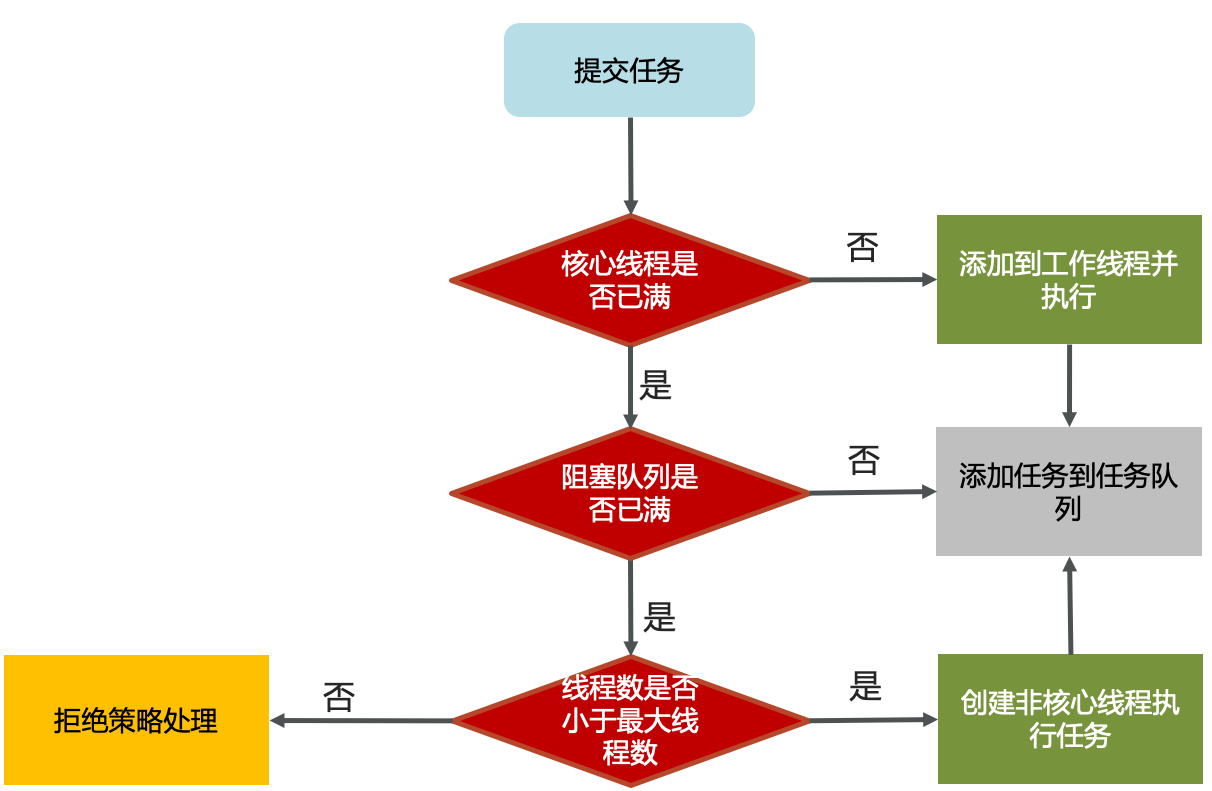
当有任务提交过来的时候,首先看核心线程是否有可用的,
- 如果核心线程还有可用的,直接是使用核心线程处理
- 如果核心线程没有可用的,此时查看阻塞队列是否已满
- 阻塞队列没有满,那么将任务存入阻塞队列
- 阻塞队列已经满了,
- 如果当前线程数已经大于最大线程数了,那么直接采用对应的拒绝策略处理
- 如果当前线程数小于等于最大线程数,那么就创建非核心线程执行任务。
- 在核心线程和非核心线程执行完成任务之后,都会检测阻塞队列是否有任务需要执行
常见的拒绝策略:
- AbortPolicy:直接抛出异常,默认策略;
- CallerRunsPolicy:用调用者所在的线程来执行任务;
- DiscardOldestPolicy:丢弃阻塞队列中靠最前的任务,并执行当前任务;
- DiscardPolicy:直接丢弃任务;
20. 阻塞队列
- ArrayBlockingQueue:基于数组结构的有界阻塞队列,FIFO。
- LinkedBlockingQueue:基于链表结构的有界阻塞队列,FIFO。
- DelayedWorkQueue :是一个优先级队列,它可以保证每次出队的任务都是当前队列中执行时间最靠前的
- SynchronousQueue:不存储元素的阻塞队列,每个插入操作都必须等待一个移出操作。
- ArrayBlockingQueue和LinkedBlockingQueue的区别:
- LinkedBlockingQueue默认无界,支持有界;ArrayBlockingQueue强制有界
- 底层是链表;底层是数组
- 有头尾两把锁,只会锁住这两个位置;一把锁,锁住整个数组
21. 如何确定线程池中核心线程数
- 高并发、任务执行时间短( CPU核数+1 ),减少线程上下文的切换并发不高、任务执行时间长
- IO密集型(文件读写、DB读写、网络请求等)任务(CPU核数 * 2 + 1)
- 计算密集型(计算型代码、Bitmap转换、Gson转换等)任务( CPU核数+1 )
22. 线程池种类
newFixedThreadPool:固定线程数的线程池
public static ExecutorService newFixedThreadPool(int nThreads) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
- 核心线程数与最大线程数一样,没有救急线程
- 阻塞队列是LinkedBlockingQueue,最大容量为Integer.MAX_VALUE
- 不推荐使用:原因:因为阻塞队列是LinkedBlockingQueue,会无线扩容,会造成堆内存溢出问题。
- newSingleThreadExecutor:单线程化的线程池,只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO)执行
```java
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService(
new ThreadPoolExecutor(1, 1,
0L,
TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()));
}核心线程数和最大线程数都是1
阻塞队列是LinkedBlockingQueue,最大容量为Integer.MAX_VALUE
不推荐使用:原因:因为阻塞队列是LinkedBlockingQueue,会无线扩容,会造成堆内存溢出问题。
newCachedThreadPool:可缓存线程池;
1
2
3
4
5
6public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}- 核心线程数为0
- 最大线程数是Integer.MAX_VALUE
- 阻塞队列为SynchronousQueue:不存储元素的阻塞队列,每个插入操作都必须等待一个移出操作。
- 不推荐使用:原因:因为可以大量线程,导致栈溢。
ScheduledThreadPoolExecutor:延迟/周期任务线程池
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,new DelayedWorkQueue());
}
public ScheduledThreadPoolExecutor(int corePoolSize, ThreadFactory threadFactory) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS, new DelayedWorkQueue(), threadFactory);
}
public ScheduledThreadPoolExecutor(int corePoolSize, RejectedExecutionHandler handler) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS, new DelayedWorkQueue(), handler);
}
public ScheduledThreadPoolExecutor(int corePoolSize,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS, new DelayedWorkQueue(), threadFactory, handler);
}
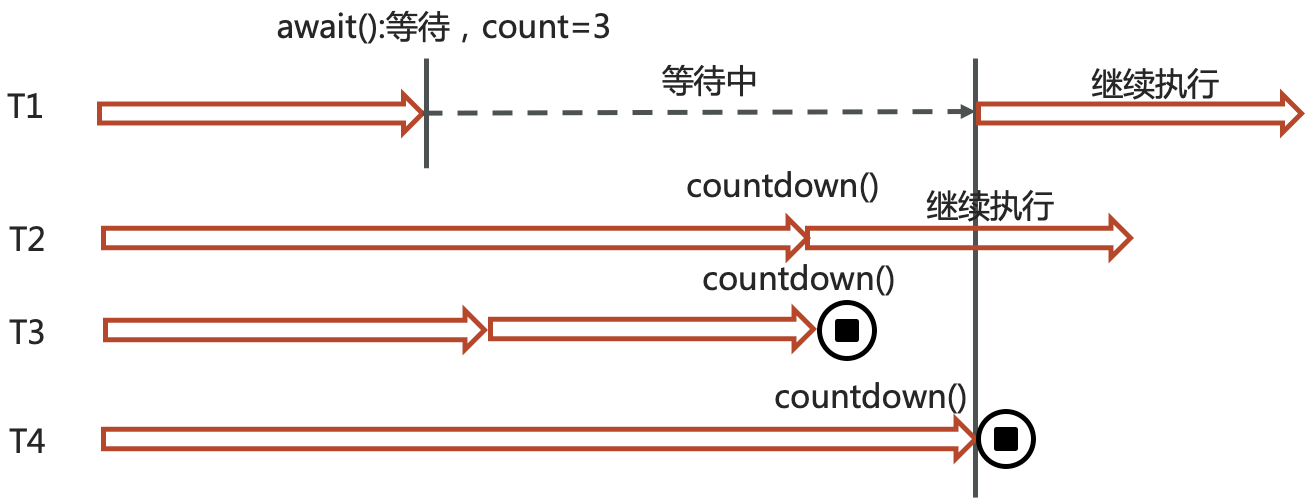
23. CountdownLatch
CountDownLatch(闭锁/倒计时锁)用来进行线程同步协作,等待所有线程完成倒计时(一个或者多个线程,等待其他多个线程完成某件事情之后才能执行)
其中构造参数用来初始化等待计数值
await() 用来等待计数归零
countDown() 用来让计数减一
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47public class CountDownLatchDemo {
public static void main(String[] args) throws InterruptedException {
//初始化了一个倒计时锁 参数为 3
CountDownLatch latch = new CountDownLatch(3);
new Thread(() -> {
System.out.println(Thread.currentThread().getName()+"-begin...");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
//count--
latch.countDown();
System.out.println(Thread.currentThread().getName()+"-end..." +latch.getCount());
}).start();
new Thread(() -> {
System.out.println(Thread.currentThread().getName()+"-begin...");
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
//count--
latch.countDown();
System.out.println(Thread.currentThread().getName()+"-end..." +latch.getCount());
}).start();
new Thread(() -> {
System.out.println(Thread.currentThread().getName()+"-begin...");
try {
Thread.sleep(1500);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
//count--
latch.countDown();
System.out.println(Thread.currentThread().getName()+"-end..." +latch.getCount());
}).start();
String name = Thread.currentThread().getName();
System.out.println(name + "-waiting...");
//等待其他线程完成
latch.await();
System.out.println(name + "-wait end...");
}
}
24. Semaphore
使用Semaphore,可以通过其限制执行的线程数量
使用步骤:
创建Semaphore对象,可以给一个容量
semaphore.acquire(): 请求一个信号量,这时候的信号量个数-1(一旦没有可使用的信号量,也即信号量个数变为负数时,再次请求的时候就会阻塞,直到其他线程释放了信号量)
semaphore.release():释放一个信号量,此时信号量个数+1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30public class SemaphoreCase {
public static void main(String[] args) {
// 1. 创建 semaphore 对象
Semaphore semaphore = new Semaphore(3);
// 2. 10个线程同时运行
for (int i = 0; i < 10; i++) {
new Thread(() -> {
try {
// 3. 获取许可,计数-1
semaphore.acquire();
} catch (InterruptedException e) {
e.printStackTrace();
}
try {
System.out.println("running...");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("end...");
} finally {
// 4. 释放许可 计数+1
semaphore.release();
}
}).start();
}
}
}
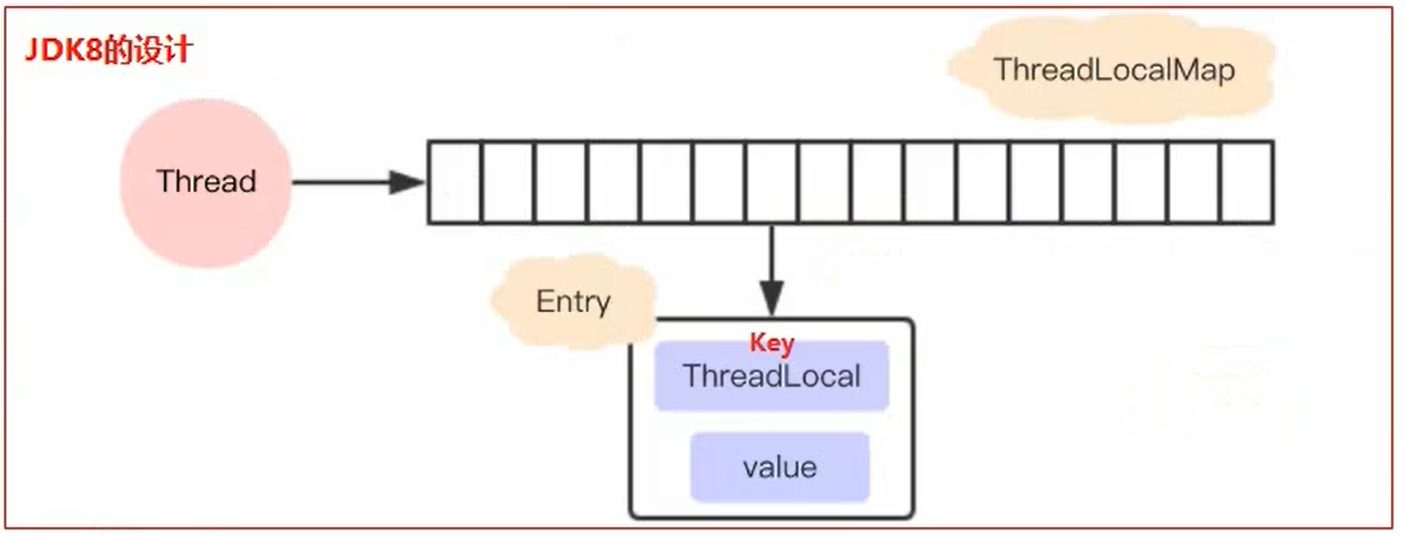
25. ThreadLocal
- ThreadLocal本质来说就是一个线程内部存储类,从而让多个线程只操作自己内部的值,从而实现线程数据隔离
- 每个线程持有一个ThreadLocalMap对象,ThreadLocalMap中为每一个线程都维护了一个数组table(存储数据)
25.1 set
1 | |
1 | |
1 | |
25.2 get
1 | |
1 | |
25.3 remove
1 | |
25.4 ThreadLocal的内存泄漏
每一个Thread维护一个ThreadLocalMap,在ThreadLocalMap中的Entry对象继承了WeakReference。其中key为弱引用,value为强引用
static class Entry extends WeakReference<ThreadLocal<?>> { /** The value associated with this ThreadLocal. */ Object value; Entry(ThreadLocal<?> k, Object v) { super(k); value = v; } }因此在GC的时候就会进行回收掉key,而value不会被回收,因此造成内存泄漏
解决:每次使用完成之后都调用remove方法